Updated: August 7, 2018 and August 27, 2018.
This article illustrates how to create a Next-Generation Clustered Heat Map (NG-CHM) using our web-based interactive builder. The web-based interactive builder is suitable for building small to moderate sized single maps (at most a few thousand elements on any axis). If you want to build larger maps, or build a suite of maps programmatically, our Galaxy- or R-based environments are more suitable. Please see our videos NG-CHM Heat Map Creation in Galaxy or How to create Next-Generation Clustered Heat Maps in R-Studio for details.
To create an NG-CHM you need a matrix of data. The matrix must include row and column labels: for instance, sample identifiers and gene labels. The interactive builder requires that this matrix is stored in a file in one of the following three formats:
- If the file’s extension is ‘.xlsx’ the file interpreted as a Microsoft Excel spreadsheet. (If the file contains multiple sheets, currently only the first sheet will be loaded.)
- If the file’s extension is ‘.csv’ the file will be interpreted as a comma-separated values file.
- For all other file extensions (e.g. ‘.txt’) the file will be interpreted as a tab-separated-value (tsv) format.
If you would just like to try the system for now, we have included a small sample data matrix that can be used instead of your own data. The example in this article will use this sample data.
Uploading the Data
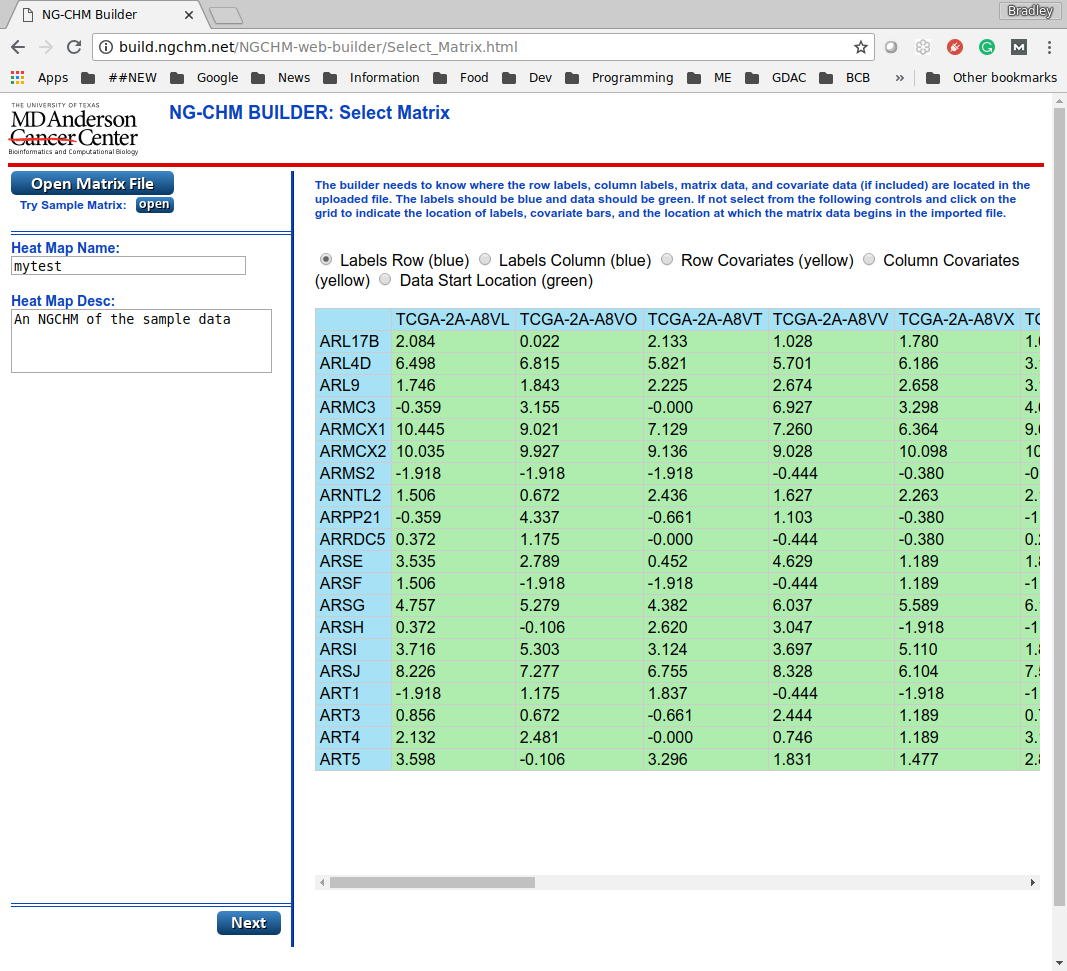
Open the first page of the interactive builder. To upload your own data, click the “Open Matrix File” button and select the file containing your data. To use the sample data, click the “Open” button beside “Try Sample Matrix”.
After the file has loaded, a preview of the top-left part of the file is displayed in the right panel. (Note: at this stage only the first few rows and columns are displayed.) The regions of the input file containing the data matrix should be displayed in green and the row and column labels in blue. If you’re using the sample data, these regions will have already been selected correctly. If you’re using your own data, you can adjust these regions, if needed, by selecting the appropriate radio button and then clicking on the top-left of the corresponding region.
Although the sample data does not, it is also possible to have covariate data included in the matrix file. If you have covariate data embeddded in the matrix file, select the appropriate radio button and click the top-left of the covariate data region, which will be highlighted in yellow. Covariate data will be described in more detail later.
Complete the Heat Map Name and Heat Map Desc fields. The builder page should look like this:
Transforming / Filtering the Data
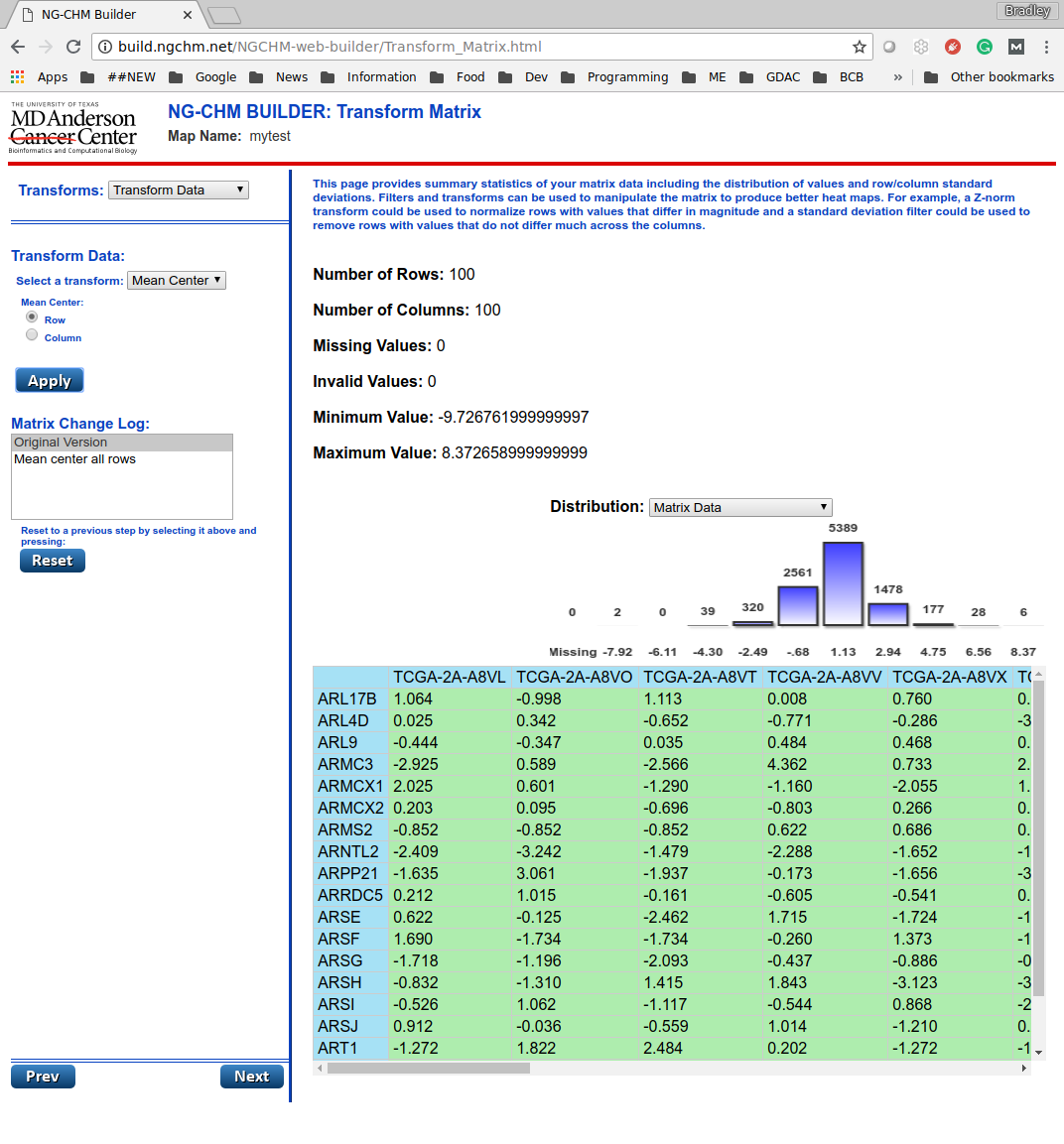
Clicking next takes you to the transform page. This page implements several common data cleaning steps that are frequently needed to transform raw data into data suitable for building a heat map. The page implements three major categories of transformations:
- Replace invalid or missing values. The data summary on the right shows the number of invalid and missing entries in the data. Map generation cannot proceed until all invalid entries have been removed.
- Filter data. The data summary on the right shows the total number of rows and columns. Data filters can be used to reduce the number of data points on either
axis to a reasonable number. The sample data does not need any data filtering. The interactive builder works best for no more than about 1000 elements per axis,
but you can use up to
2000 elements per axis. Update: You can now use at most 4000 elements total (rows and columns combined) and at most 3500 elements on any axis. So, 2000 by 2000 is the largest square matrix, and 3500 by 500 is the largest rectangular matrix. - Transform data. You can apply one or more simple data transform steps. Since the sample data is gene expression data, subtracting average gene expression from each row will result in a more pleasing heat-map.
The figure below shows the data after row-centering.
Update: You can download the modified data matrix using the “Get Edited Matrix” button on the top-right of the right-hand pane.
Adding Covariate Bars
The next page allows covariate bars to be added to the heat map. Covariate bars are side bars that add descriptive information about the rows or columns
to the heat map. If you supplied your own data, you can also add your own covariates. If (and only if) you used
the sample data, clicking “Add” gives you a choice of four sample covariates. Selecting ‘Age’ and clicking Upload adds the Age covariate data to the NG-CHM.
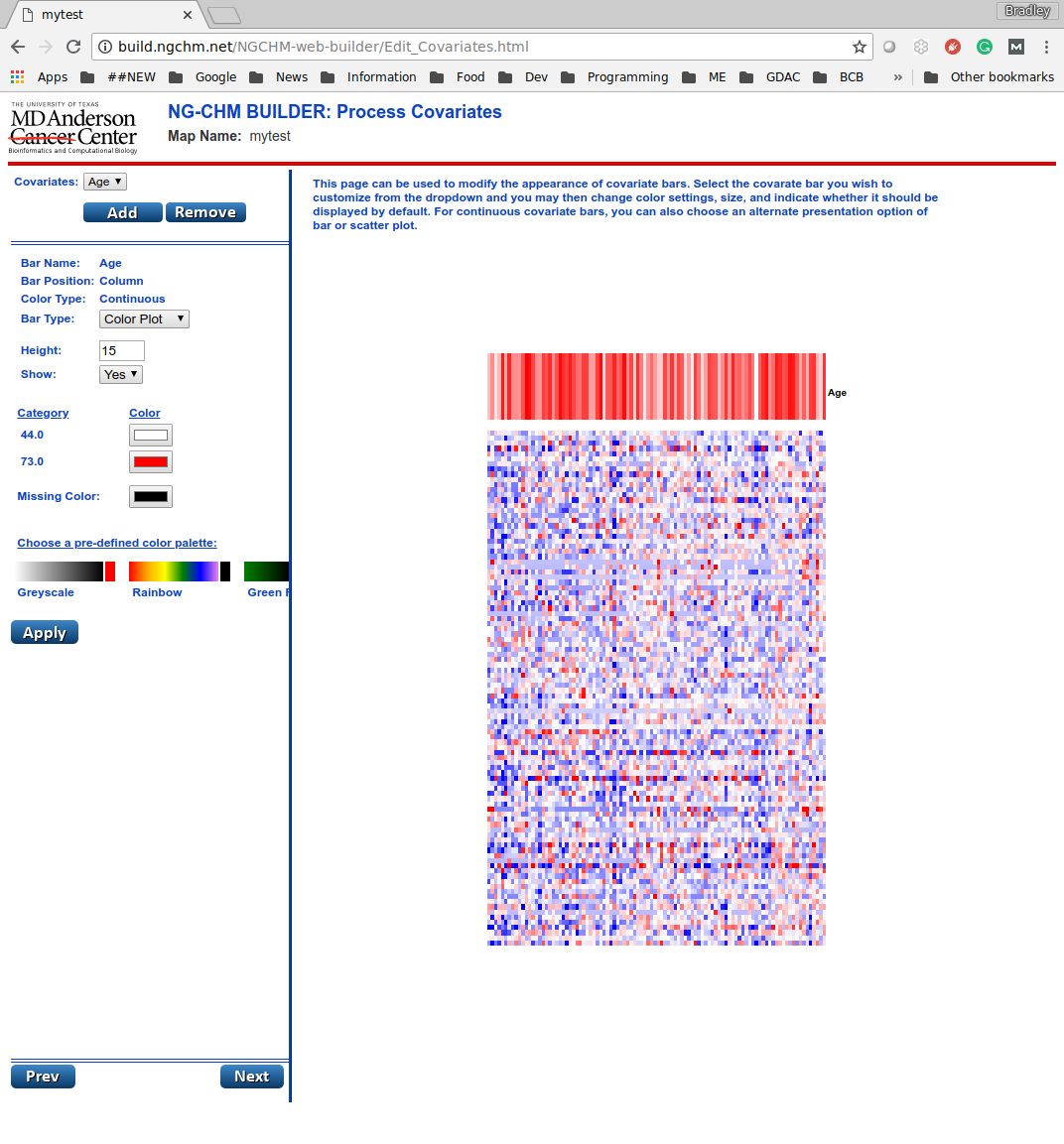 Since it’s example data, the bar position (Column) and covariate color type (Continuous) are predetermined.
Since it’s example data, the bar position (Column) and covariate color type (Continuous) are predetermined.
If you provided your own matrix data, clicking ‘Add’ will be enable you to select your own file containing covariate data. You will also be required to name the covariate bar, choose the axis to which it applies, and select whether its data type is discrete or continuous.
For both the example covariates and user-supplied covariates, you can also choose the type of bar display (a standard color bar, a histogram, or a scatter plot), the height of the bar, and its color scheme.
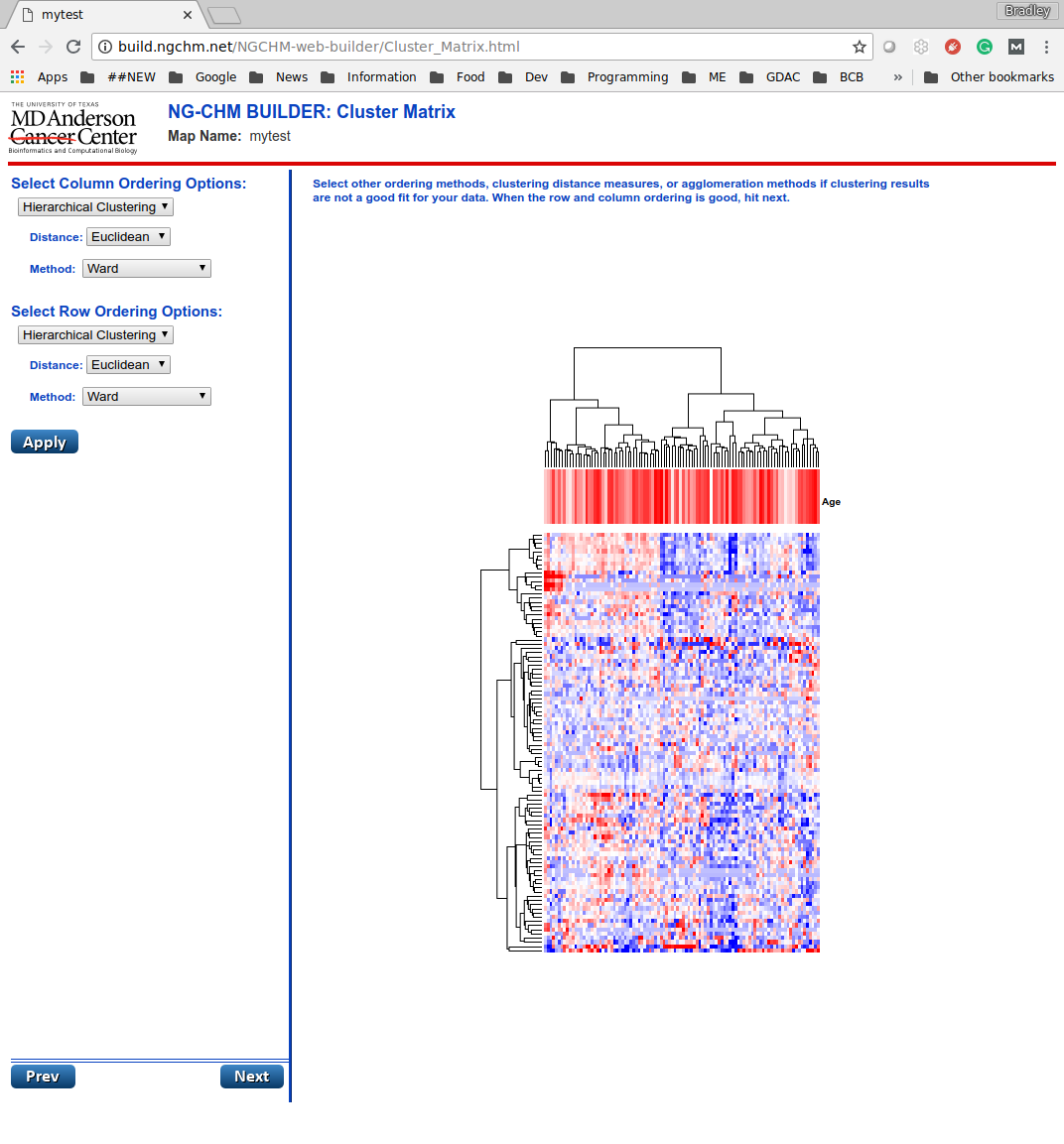
Setting Row and Column Ordering
The next page allows you to choose the row and column orderings to apply. By default, each axis is ordered by “original” order: the order of rows and columns in the input data file.
To try a different ordering, select the desired orderings for the rows or columns. For hierarchical clustering also select the desired distance metric and agglomeration method.
When Apply is clicked the system will update the thumbnail with the desired ordering. For large matrices there may be a short delay if hierarchical clustering is required.
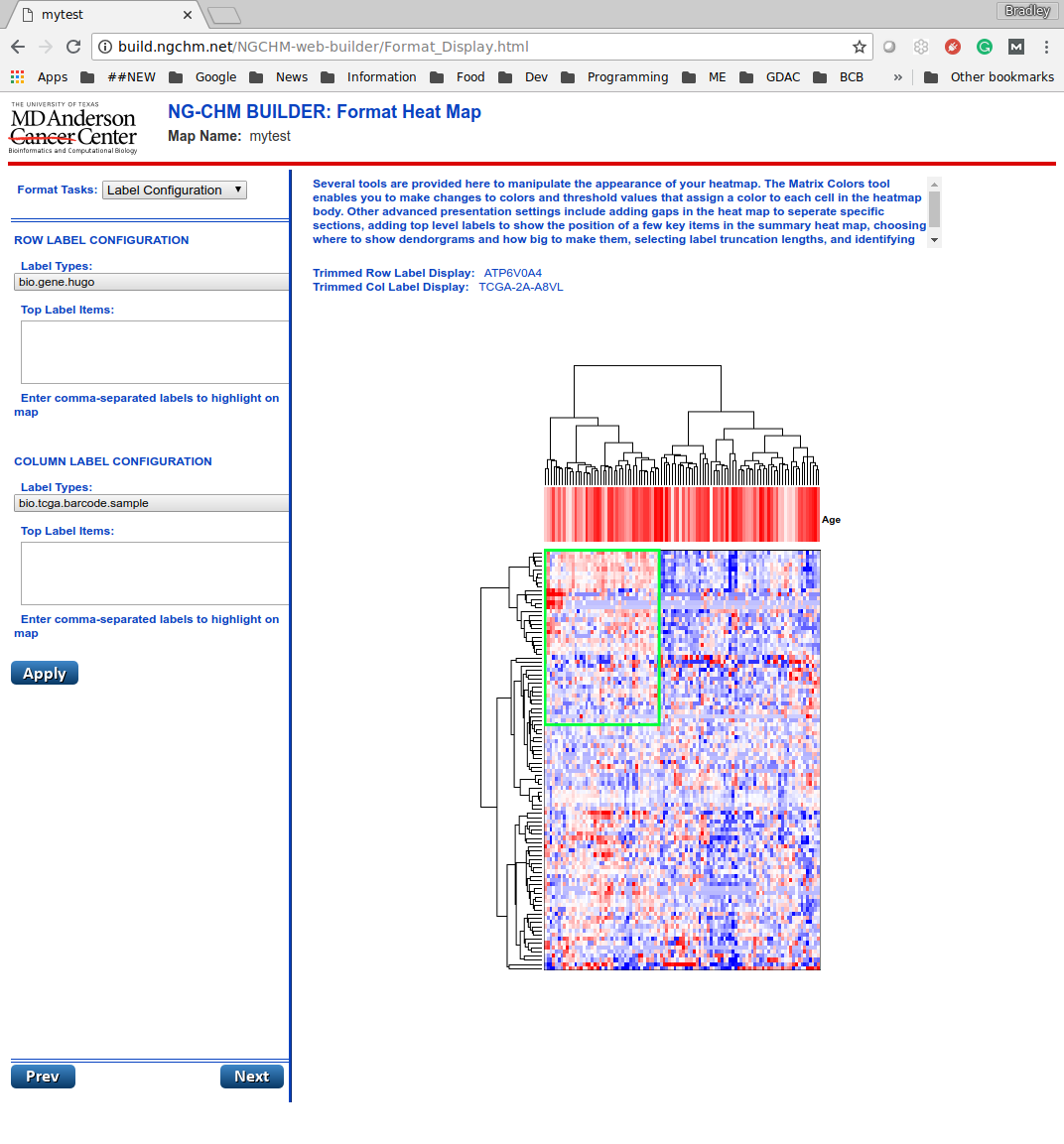
Formatting the Heat Map
The next page allows you to customize the appearance of the heat map. The “Format Tasks” drop-down at the top-left gives four options:
- Matrix Colors/Breaks. Lets you modify the heat map’s initial color scheme.
- Heat Map Display. Lets you modify the display of dendrograms, label length, selection color.
- Heat Map Gaps. Lets you insert gaps into the heat map.
- Label Configuration. Lets you configure the label types used to determine link-outs.
For the sample data, row labels are genes (bio.gene.hugo) and column labels are TCGA sample identifiers (bio.tcga.barcode.sample). A database
describing in detail the available label types is under development and will be incorporated into a future release of the builder.
In the interim, a table of link out types is available here.
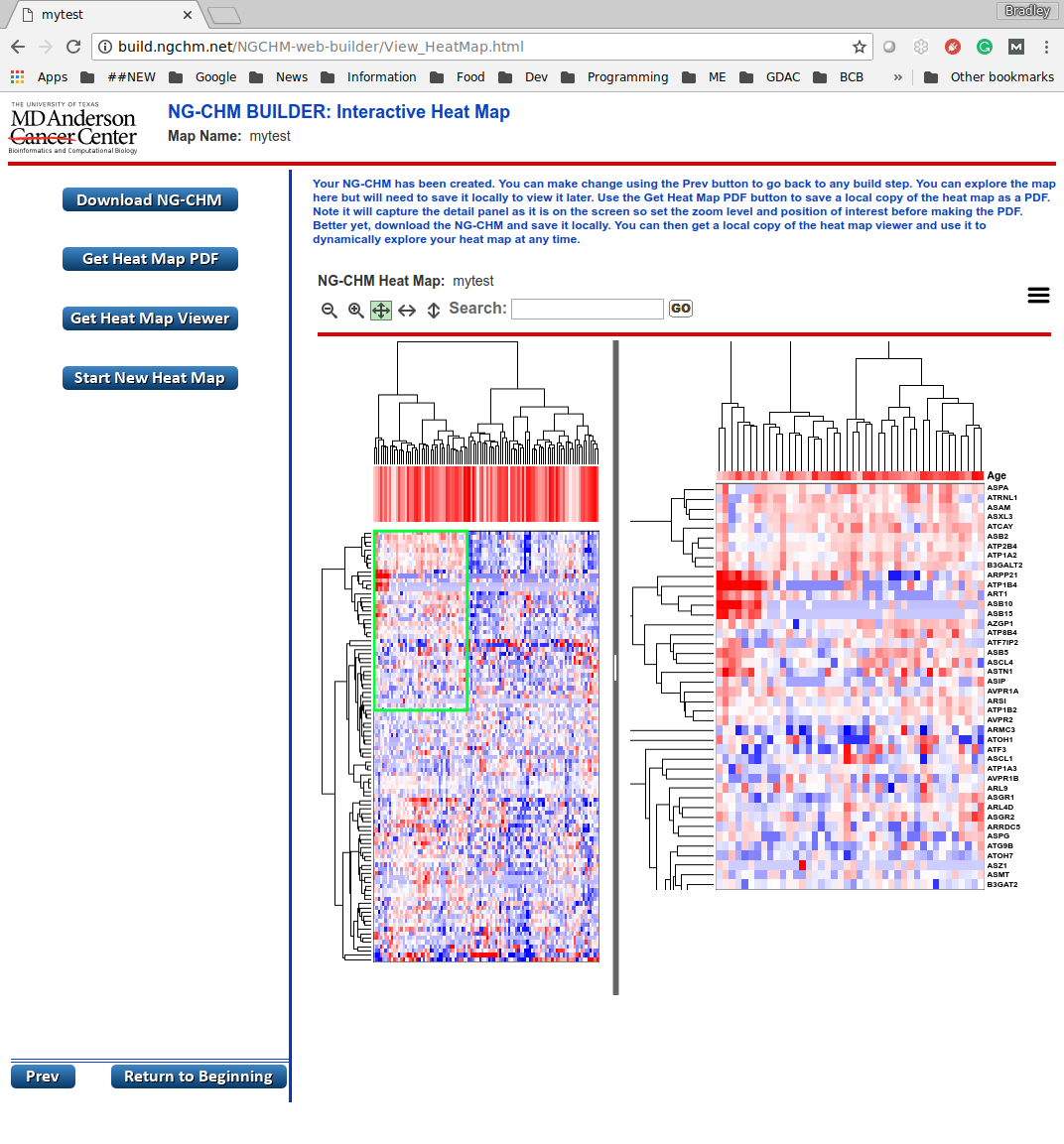
Viewing the Heat Map
The following (last) page displays the completed NG-CHM. You can explore the generated NG-CHM.
 Update: Clicking the “Expand Map” button at the top of the right-hand pane will expand the viewer to fill the browser
window. Click “Collapse Map” to return to the builder interface.
Update: Clicking the “Expand Map” button at the top of the right-hand pane will expand the viewer to fill the browser
window. Click “Collapse Map” to return to the builder interface.
For a brief summary of the map configuration options available in the viewer’s ‘hamburger’ menu, please see this video.
The “Download NG-CHM” button saves a copy of the NG-CHM for viewing later. This is the only way to keep a copy of your NG-CHM. If needed, you can also download a copy of the Heat Map Viewer by clicking on the ‘Get Heat Map Viewer’ button.
You can also generate a PDF version of the map.
To generate another NG-CHM, you can click on the ‘Return to Beginning’ button at the bottom of the left panel, or goto the ‘Builder’ option on the site’s menu bar.